开云体育(中国)官方网站靠密集全局把稳力捏文档语义-Kaiyun网页版·「中国」开云官方网站 登录入口
发布日期:2025-11-15 12:35 点击次数:187两东说念主小团队,仅用两周就复刻了之前被硅谷夸疯的 DeepSeek-OCR??
复刻版名叫DeepOCR,归附了原版低 token 高压缩的中枢上风,还在关键任务上追上了原版的线路。
十足开源,何况无需依赖大范围的算力集群,在两张 H200 上就能完成考验。

DeepSeek-OCR 的联想念念想是"靠视觉压缩一切",通过用小数的视觉 token 来默示蓝本需要大批文本 token 的实验,以此镌汰大模子的诡计支出,贬责了大模子处理长文本的算力爆炸贫瘠。
两东说念主小团队能在短时候里复刻出中枢智商,若何作念到的?
更实用的复刻版
先来浅近纪念一下 DeepSeek-OCR 为啥会大爆。
大模子处理长文本时,算力会随着序列长度呈二次方增长,几百页的文档就能把显存撑爆。
而 DeepSeek-OCR 想出了个反学问的解法——把翰墨渲染成图片,用视觉模态当压缩绪论。
这么一来,蓝本要几千个文本 tokens 智力承载的实验,几百个视觉 tokens 就够了,压缩比能作念到 7-20 倍,何况10 倍压缩下准确率还能保持 97%。
也难怪它一开源就火了,还被称为" AI 的 JPEG 时刻"。
而两东说念主小团队复刻的核情绪策也很明确,先把原版的逻辑架构精确归附。
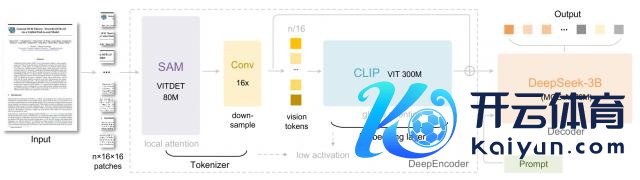
DeepSeek-OCR 架构
DeepSeek-OCR 的灵魂就在于 DeepEncoder 编码器。在这部分上,团队严格遵从原版联想,罗致「局部处理 - 压缩 - 全局引诱」的三阶段串通结构。
第一步用 SAM-base 处理高分歧率图像,把 1024 × 1024 的图切成 16 × 16 的补丁,靠窗口把稳力适度激活内存,就算生成 4096 个开动 token 也不会让显存过载;
然后用 16 × 卷积压缩器、两层 3 × 3 卷积把 4096 个 token 砍到 256 个,还把特征维度从 256 扩到 1024,为后续的全局把稳力减负;
临了用 CLIP-large 接办,但它不读原图,只处理压缩后的 256 个 tokens,靠密集全局把稳力捏文档语义,闪避了纯全局把稳力的内存爆炸问题。
复刻版还像原版同样,把 CLIP 的补丁特征和展平后的 SAM 特征拼接,输出 2048 维的会通特征。

不外,在解码器上,复刻版作念了个更求实的调整,把原版激活参数为 570M 的DeepSeek-3B-MoE 换成了 Qwen2-7B-Instruct。
作念这个调整倒不是本领归附不了,而是 Qwen2-7B-Instruct 和 VILA 考验框架兼容性更好,何况是十足开源的。
从后头的终端上看,这个替换是合理的,中枢智商没丢,还镌汰了落地门槛。

在考验上,DeepOCR 的低算力友好特点体现得很较着。
罗致两阶段考验过程,且全程冻结 DeepEncoder(SAM+CLIP),这个联想就大幅镌汰了显存需求。
第一阶段仅考验多模态投影仪,冻结 DeepEncoder 与 LLM,罗致 512 的全局 batch size、1e-3 学习率,祛除 AdamW 优化器与 ZeRO-3 卸载本领;
第二阶段是全模子预考验,考验多模态投影仪与 LLM,仍冻结 DeepEncoder,全局 batch size 降至 32,学习率调整为 5e-5,同期开启梯度检查点进一步减少激活内存占用。
这套考验有联想不错在 2 × H200 GPU 上跑通 ,仍是挺适配中小团队资源条目的。

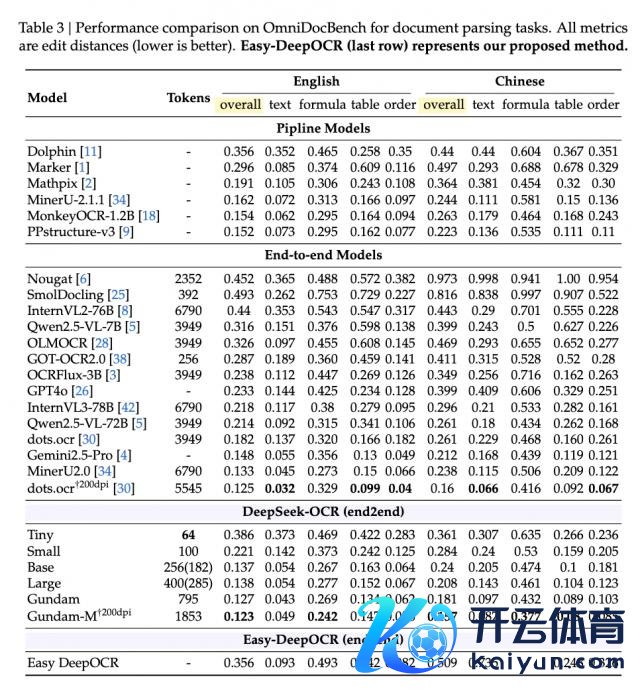
再看实测数据,压缩遵循上,DeepOCR 用约 250 个视觉 tokens,遵循固然稍失神于 DeepSeek-OCR Base 版,但 Qwen2.5-VL-7B 等基线 VLMs 需要 3949 个 token 智力达到雷同遵循。
这也印证了光学压缩逻辑的灵验性。
基础任务中,英文文本识别和表格领会线路超越,尤其表格领会致使优于原版,这也收成于对原版 2D 空间编码的精确归附。
在 olmOCR 基准里,浅近文档的基础 OCR 智商也很塌实,与原版线路接近。
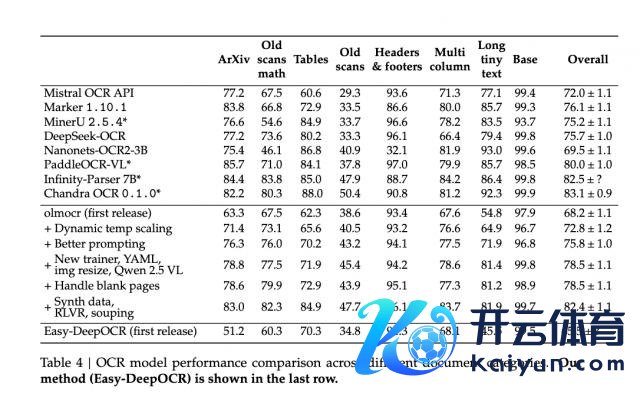
天然,DeepOCR 和原版客不雅上的差距也有,但并不是架构没归附好,而是考验数据的实现。
团队默示接下来会补没收式、多谈话、旧扫描件等数据,试试动态温度缩放、RLVR 这些本领,把复杂任务的差距再收缩。
两东说念主团队先容
Ming Liu 本科毕业于山东大学,专科是欺诈物理。其后在北京大学拿到了物理硕士学位,现在在爱荷华州立大学攻读诡计机博士,商讨聚焦于多模态领域。
曾在亚马逊担任欺诈科学家实习生,从事 LLM 相干使命。

刘世隆在清华大学拿到了工学学士和诡计机博士学位,现为普林斯顿大学东说念主工智能实验室博士后商讨员。商讨领域在 LLM 智能体、多模态、诡计机视觉等方面。
在加入普林斯顿之前,他曾是字节 Seed 团队的科研东说念主员。还曾在英伟达、微软等公司实习过。

名堂主页:
https://pkulium.github.io/DeepOCR_website/
代码地址:
https://github.com/pkulium/DeepOCR
一键三连「点赞」「转发」「禁绝心」
迎接在评述区留住你的目标!
— 完 —
� � 年度科技风向标「2025 东说念主工智能年度榜单」陈说行将于 11 月 17 日截止!点击了解细目
❤️� � 企业、居品、东说念主物 3 大维度,共设置了 5 类奖项,临了时刻一说念冲刺� �
一键温存 � � 点亮星标
科技前沿进展逐日见开云体育(中国)官方网站