开云(中国)kaiyun网页版登录入口在编程智能体中罢了了R1的器用调用-Kaiyun网页版·「中国」开云官方网站 登录入口
发布日期:2026-04-03 11:27 点击次数:188
1月临了一天,DeepSeek的热度依旧飞扬。在好意思国,不管是AI从业者仍是平时巨匠,都感受到了来自中国AI时候的冲击。Anthropic CEO命令好意思国加强芯片料理,而OpenAI则寻求高达400亿好意思元的融资。网友们诓骗宽松的开源许可,制作了使用DeepSeek-R1替代OpenAI Operator的教程开云(中国)kaiyun网页版登录入口,无需200好意思元订阅,都备免费。

英伟达对DeepSeek赞许有加,并晓示DeepSeek-R1认真登陆NVIDIA NIM。在单个NVIDIA HGX H200系统上,竣工版DeepSeek-R1 671B的处理速率可达3,872 Token/秒。亚马逊也在Amazon Bedrock和SageMaker AI中上线了DeepSeek-R1模子。微软甚而提前将DeepSeek-R1部署在其云处事Azure上。
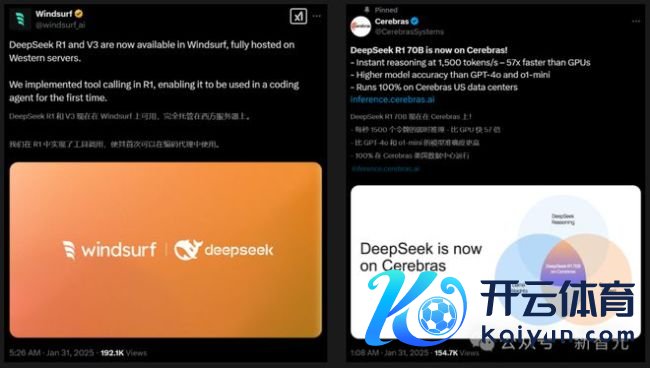
除了科技巨头,初创公司也收拢契机。Windsurf裁剪器集成了DeepSeek-R1和V3模子,在编程智能体中罢了了R1的器用调用。Cerebras宣称其部署的70B模子不仅比GPU快57倍,还在准确率上迥殊了GPT-4o和o1-mini。
吴恩达以为,围绕DeepSeek的热议显现了几个紧迫趋势:中国在生成式AI领域正在赶上好意思国。尽管ChatGPT推出时好意思国昭彰开端,但跟着Qwen、Kimi、InternVL和DeepSeek等模子的出现,中国的差距赶快松开。尽头是在视频生成等领域,中国已展现出一些开端上风。
DeepSeek-R1不仅开源了模子权重,还共享了一份详备的时候敷陈。比拟之下,一些好意思国公司通过渲染AI危机来股东规章拦阻开源发展。吴恩达指出,如若好意思国络续妨碍开源,这一要领可能由中国主导。
怒放权重模子加快了LLM的Token价钱下跌,为配置者提供了更多选择。举例,OpenAI的输出价钱为60好意思元/百万Token,而DeepSeek R1只需2.19好意思元。历练基础模子并提供API处事充满挑战,许多公司仍在寻找收回本钱的步调。但在基础模子之上进行应用配置,则充满了商机。

对于通过扩大模子范围股东越过的不雅点好多,但DeepSeek团队因好意思国AI芯片禁令不得不在性能较低的H800 GPU上驱动模子,这促使他们在优化方面进行了无数立异。最终,模子历练本钱(不包括推敲本钱)不到600万好意思元。吴恩达以为,即使智能变得更低廉,东谈主类仍会使用更多智能。

DeepSeek的得胜引起了英特尔前CEO Pat Gelsinger的柔和。他以为,针对DeepSeek的反映淡薄了计较机发展过程中的三个教学:计较征服“气体定律”,工程的实质是搪塞敛迹,以及怒放终将成功。DeepSeek展示了如安在资源受限的情况下以低得多的本钱寄托天下一流处分有策画。此外,怒放的推敲和生态系统对于AI的将来发展至关紧迫。